Competitive Network
A competitive network is a collection of neurons that compete with each other to represent clusters of inputs. With training, the nodes of a competitive network should come to represent a particular cluster of inputs.
The competitive network combines elements of winner take all networks and Hebbian learning. The self-organizing-map is a generalization of this algorithm.
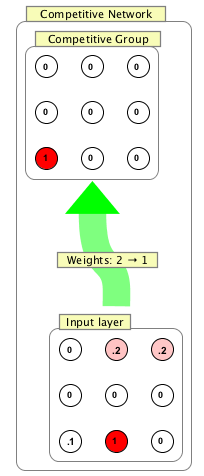
A competitive network may either be created as a group or a network. As a network, it has a self-contained layer of input nodes and it can be trained using a table of inputs. As a group, it is up to the user to connect it to other neurons, and the inputs these produce will determine its weights to it over time.
Algorithm
The basic algorithm described here is the original PDP version due to Rumelhart and Zipser. An alternative, due to Alvarez and Squire, is also available(see references below).
1) Compute the weighted input to every unit.
2) Determine the winner, which is the unit with the greatest weighted input. In the case of a tie this is done arbitrarily.
3) Update the weights attaching to the winning neuron only. These weights are changed by the following quantity: learning rate times the source activation divided by the total activation of the source layer minus the current strength of the weight:
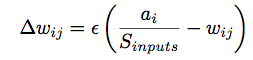
ε is a learning rate. Sinputs is the sum of all the inputs to the unit, and ai is an input neuron's activation. This algorithm has the result that the winning unit's weights come over time to resemble the input vector that led that unit to win. The learning rate controls how quickly this happens.
The division by the sum of inputs maintains the normalization of the weight vectors. Thus, if more strength is added to one weight, it is taken away from another.
Initialization
Competitive networks are initialized with some number of units, and are by default laid out as a line. There are no connections. Connections must be made leading in to the network, and they should be constrained to only take values between 0 and 1.
A variant of the competitive learning algorithm called "leaky learning" requires all weights to learn on each time step, rather than just the winning weight. The algorithm for the weight change on the losing units is the same as above, but a new learning rate parameter is used, which will typically be smaller than the winning unit learning rate, so that weights attaching to losing neurons learn more slowly.
Creation / Editing
Properties inherited from neuron group are described on the neuron group page.
Number of Competitive Neurons: Sets the number of neurons for the group.
Number of Input Neurons: Sets number of input neurons.
Update Method: Rummelhart-Zipser: The Rummelhart-Zipser method described above.
Update Method: Alvarez-Squire: The Alvarez-Squire method described in the link below in references.
Epsilon: A standard learning rate, which determines how quickly synapses change.
Winner Value: The value for the winning neuron.
Loser Value: The value for all losing neurons.
Use Leaky Learning: whether to use the leaky learning rule. Leaky learning requires all weights to learn, not just the weights attaching to the winning unit.
Leaky epsilon : The learning rate for losing neurons, when leaky learning is used.
Normalize Inputs: if selected, inputs are normalized prior to being used in setting weights.
Synapse Decay Percent: Amount to decay incoming synapses at every iteration. Cf. the Alvarez-Squire paper.
Layout: See the layouts page.
Right Click Menu
Generic right-click items are described on the neuron group page.
Edit/Train Competitive: Opens edit dialog to edit and train the competitive network.
Add Current Pattern To Input Data: Adds the current pattern in the input nodes of the network to the network's input table (viewable in the training dialog). Useful for creating a training set for a competitive network using GUI activations or activations from a larger simulation.
Train On Current Pattern: Iterate the training algorithm once using the current inputs.
Randomize Synapses: Randomize synapses connected the competitive group, which are the ones trained using the algorithm.
Training
Training a network involves specifying input data and then running the algorithm. This process is covered here.
References
The Rummelhart and Zipser update rules is described here. Also see the PDP volumes, volume 1, chapter 5.
The Alvarez and Squire version of the algorithm is describe in this PNAS paper.